ADVANCED DATA STRUCTURES
Binary Search Tree
Binary search tree is a data structure that quickly allows us to maintain a sorted list of numbers.
It is called a binary tree because each tree node has maximum of two children.
It is called a search tree because it can be used to search for the presence of a number in
O(log(n))time.
The properties that separates a binary search tree from a regular binary tree is
All nodes of left subtree are less than root node
All nodes of right subtree are more than root node
Both subtrees of each node are also BSTs i.e. they have the above two properties
The binary tree on the right isn't a binary search tree because the right subtree of the node "3" contains a value smaller that it.
There are two basic operations that you can perform on a binary search tree:
1. Check if number is present in binary search tree
The algorithm depends on the property of BST that if each left subtree has values below root and each right subtree has values above root.
If the value is below root, we can say for sure that the value is not in the right subtree; we need to only search in the left subtree and if the value is above root, we can say for sure that the value is not in the left subtree; we need to only search in the right subtree.
Algorithm:
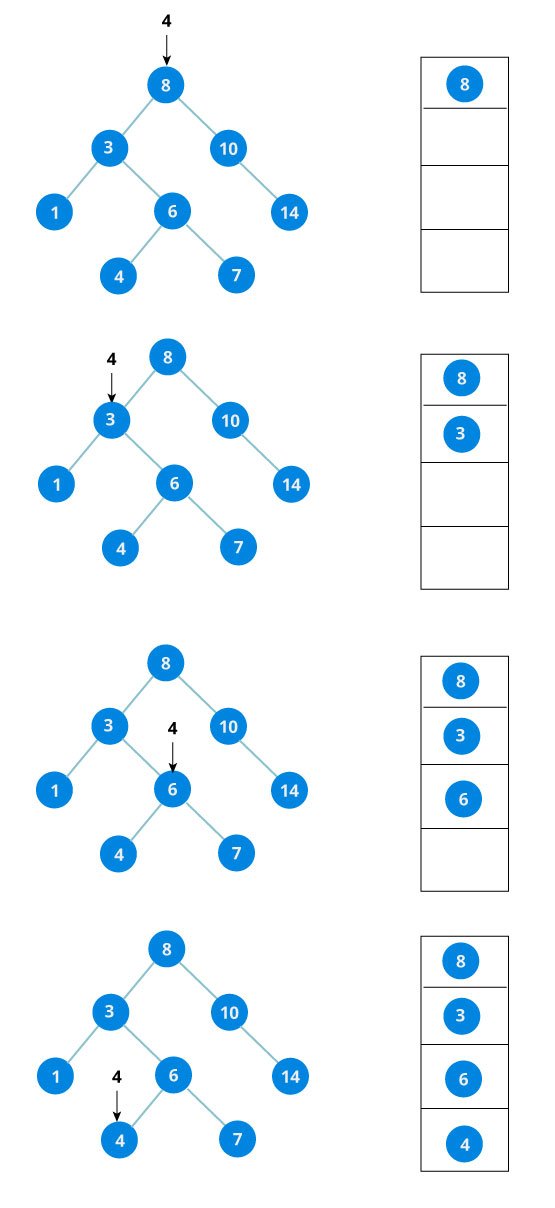
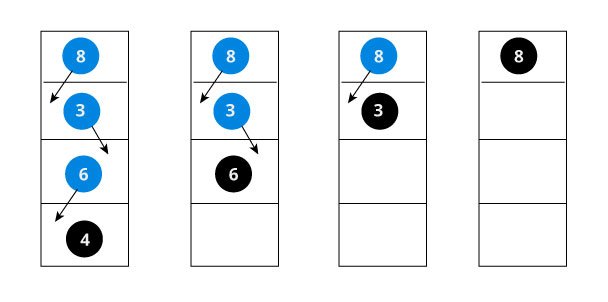
Let us try to visualize this with a diagram.
If the value is found, we return the value so that it gets propogated in each recursion step as shown in the image below.
If you might have noticed, we have called return search(struct node*) four times. When we return either the new node or NULL, the value gets returned again and again until search(root) returns the final result.
If the value is not found, we eventually reach the left or right child of a leaf node which is NULL and it gets propagated and returned.
2. Insert value in Binary Search Tree(BST)
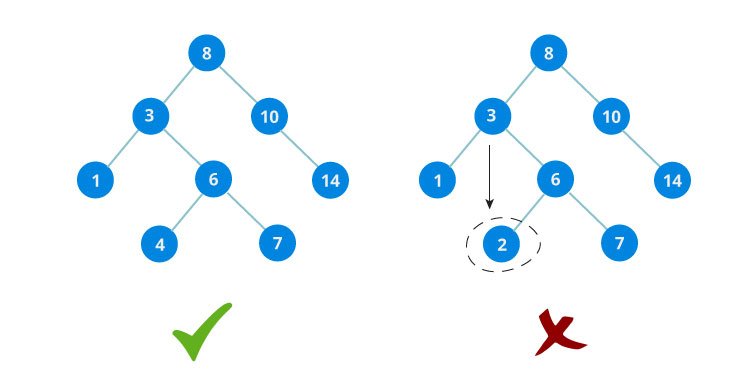
Inserting a value in the correct position is similar to searching because we try to maintain the rule that left subtree is lesser than root and right subtree is larger than root.
We keep going to either right subtree or left subtree depending on the value and when we reach a point left or right subtree is null, we put the new node there.
Algorithm:
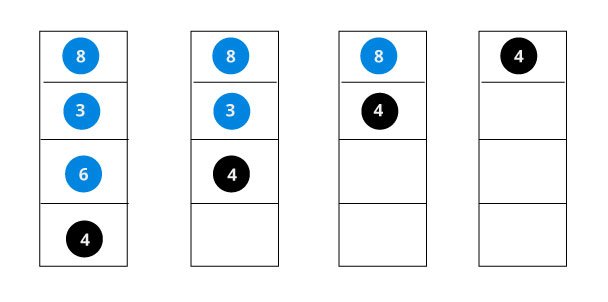
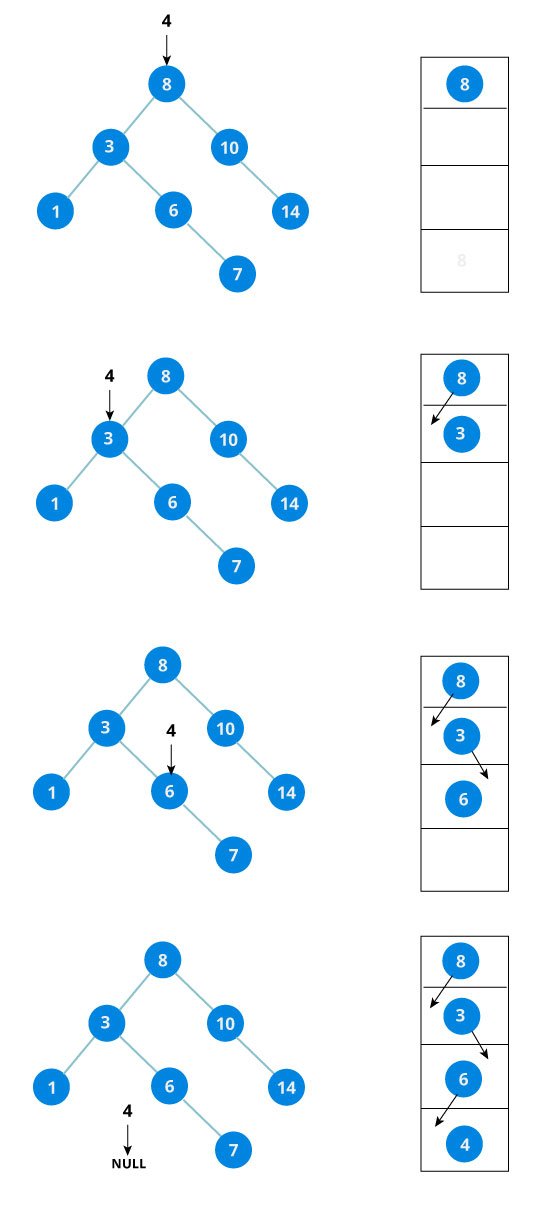
The algorithm isn't as simple as it looks. Let's try to visualize how we add a number to an existing BST.
We have attached the node but we still have to exit from the function without doing any damage to the rest of the tree. This is where the return node; at the end comes in handy. In the case of NULL, the newly created node is returned and attached to the parent node, otherwise the same node is returned without any change as we go up until we return to the root.
This makes sure that as we move back up the tree, the other node connections aren't changed.
The complete code for Binary Search Tree insertion and searching in C programming language is posted below:
The output of the program will be
Graph Data Stucture
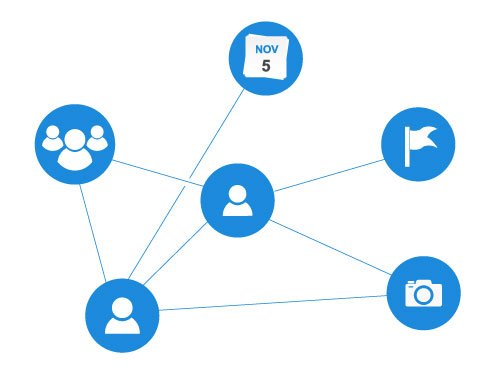
A graph data structure is a collection of nodes that have data and are connected to other nodes.
Let's try to understand this by means of an example. On facebook, everything is a node. That includes User, Photo, Album, Event, Group, Page, Comment, Story, Video, Link, Note...anything that has data is a node.
Every relationship is an edge from one node to another. Whether you post a photo, join a group, like a page etc., a new edge is created for that relationship.
All of facebook is then, a collection of these nodes and edges. This is because facebook uses a graph data structure to store its data.
More precisely, a graph is a data structure (V,E) that consists of
A collection of vertices V
A collection of edges E, represented as ordered pairs of vertices (u,v)
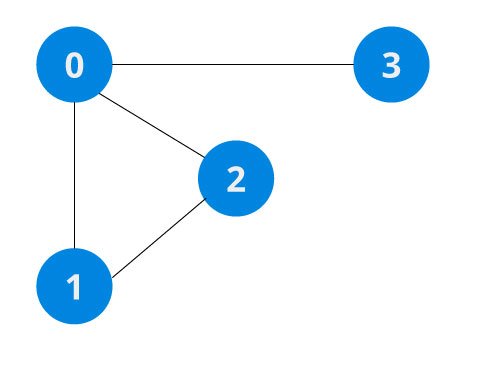
In the graph,
Graph Terminology
Adjacency: A vertex is said to be adjacent to another vertex if there is an edge connecting them. Vertices 2 and 3 are not adjacent because there is no edge between them.
Path: A sequence of edges that allows you to go from vertex A to vertex B is called a path. 0-1, 1-2 and 0-2 are paths from vertex 0 to vertex 2.
Directed Graph: A graph in which an edge (u,v) doesn't necessary mean that there is an edge (v, u) as well. The edges in such a graph are represented by arrows to show the direction of the edge.
Graph Representation
Graphs are commonly represented in two ways:
1. Adjacency Matrix
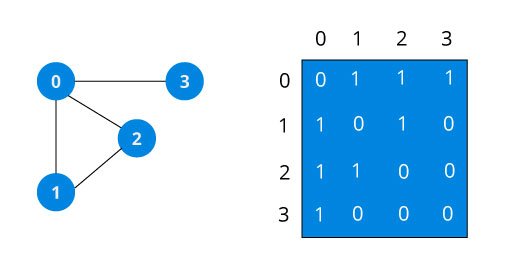
An adjacency matrix is 2D array of V x V vertices. Each row and column represent a vertex.
If the value of any element a[i][j] is 1, it represents that there is an edge connecting vertex i and vertex j.
The adjacency matrix for the graph we created above is
Since it is an undirected graph, for edge (0,2), we also need to mark edge (2,0); making the adjacency matrix symmetric about the diagonal.
Edge lookup(checking if an edge exists between vertex A and vertex B) is extremely fast in adjacency matrix representation but we have to reserve space for every possible link between all vertices(V x V), so it requires more space.
2. Adjacency List
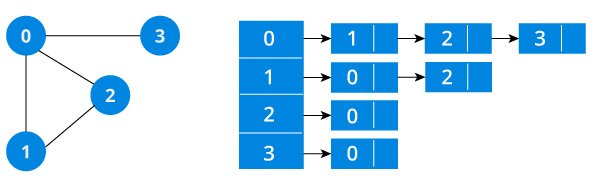
An adjacency list represents a graph as an array of linked list.
The index of the array represents a vertex and each element in its linked list represents the other vertices that form an edge with the vertex.
The adjacency list for the graph we made in the first example is as follows:
An adjacency list is efficient in terms of storage because we only need to store the values for the edges. For a graph with millions of vertices, this can mean a lot of saved space.
Adjacency List Python
There is a reason Python gets so much love. A simple dictionary of vertices and its edges is a sufficient representation of a graph. You can make the vertex itself as complex as you want.
Graph Operations
The most common graph operations are:
Check if element is present in graph
Graph Traversal
Add elements(vertex, edges) to graph
Finding path from one vertex to another
Last updated