Data Structure and Algorithms
https://www.programiz.com/dsa/
Array/Matrix
Even though both are in effect a representation of a list of lists we can use the array and numpy package.
2-D Arrays
Matrix
Sets
ChainMap
Linked List (simple)
Traverse a linked list
we need to add the following function to the SLinkedList Class:
Insertion in a Linked List
At the beginning of a linked list, we need to add
Append to a linked list
Insert in between two data nodes
Remove an item from a linked list
Doubly Linked List
We can use the same approach as in the Singly Linked List but the head and next pointer will be used for proper assignation to create two links in each of the nodes in addition to the data present in the node.
For both we can use the build-in list type but as a good default choice - if you are not looking for parallel processing support - it is recommended to use colloctions.deque. There is also queue.LifoQueue Class.
Stack
Queue
If multiprocessing is needed you can use the `multiprocessing.Queue Class`. This is a shared job queue implementation that allows queued items to be processed in parallel by multiple concurrent workers. Process-based parallelization is popular in Python due to the global interpreter lock (GIL).
multiprocessing.Queue is meant for sharing data between processes and can store any pickle-able object.
Hash Table / Dictionary
In Python, the Dictionary data types represent the implementation of hash tables. The Keys in the dictionary satisfy the following requirements.
The keys of the dictionary are hashable i.e. the are generated by hashing function which generates unique result for each unique value supplied to the hash function.
The order of data elements in a dictionary is not fixed.
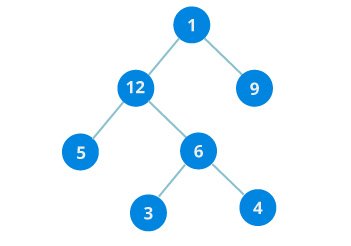
Binary Tree
Create
Tree represents the nodes connected by edges. It is a non-linear data structure. It has the following properties.
One node is marked as Root node.
Every node other than the root is associated with one parent node.
Each node can have an arbitrary number of chid node.
We can create our own tree structure using the concept of nodes from above. We designate one node as root node and then add more nodes as child nodes.
The following is definition of Binary Search Tree(BST) according to Wikipedia
Binary Search Tree, is a node-based binary tree data structure which has the following properties:
The left subtree of a node contains only nodes with keys lesser than the node’s key.
The right subtree of a node contains only nodes with keys greater than the node’s key.
The left and right subtree each must also be a binary search tree. There must be no duplicate nodes.
The above properties of Binary Search Tree provide an ordering among keys so that the operations like search, minimum and maximum can be done fast. If there is no ordering, then we may have to compare every key to search a given key.
Search
To search a given key in Binary Search Tree, we first compare it with root, if the key is present at root, we return root. If key is greater than root’s key, we recur for right subtree of root node. Otherwise we recur for left subtree.
Insertion of a key
A new key is always inserted at leaf. We start searching a key from root till we hit a leaf node. Once a leaf node is found, the new node is added as a child of the leaf node.
Heaps / queue.PriorityQueue Class
A priority queue is a container data structure that manages a set of records with totally-ordered keys (for example, a numeric weight value) to provide quick access to the record with the smallest or largest key in the set.
Graphs
We can present this graph in a python program as below.
When the above code is executed, it produces the following result −
We can create our own dict like above or can use collections.defaultdict , for example:
Algorithm Design
Algorithm is a step-by-step procedure, which defines a set of instructions to be executed in a certain order to get the desired output. Algorithms are generally created independent of underlying languages, i.e. an algorithm can be implemented in more than one programming language.
From the data structure point of view, following are some important categories of algorithms:
Search − Algorithm to search an item in a data structure.
Sort − Algorithm to sort items in a certain order.
Insert − Algorithm to insert item in a data structure.
Update − Algorithm to update an existing item in a data structure.
Delete − Algorithm to delete an existing item from a data structure.
Characteristics of an Algorithm
Not all procedures can be called an algorithm. An algorithm should have the following characteristics:
Unambiguous − Algorithm should be clear and unambiguous. Each of its steps (or phases), and their inputs/outputs should be clear and must lead to only one meaning.
Input − An algorithm should have 0 or more well-defined inputs.
Output − An algorithm should have 1 or more well-defined outputs, and should match the desired output.
Finiteness − Algorithms must terminate after a finite number of steps.
Feasibility − Should be feasible with the available resources.
Independent − An algorithm should have step-by-step directions, which should be independent of any programming code.
How to Write an Algorithm?
There are no well-defined standards for writing algorithms. Rather, it is problem and resource dependent. Algorithms are never written to support a particular programming code.
As we know that all programming languages share basic code constructs like loops (do, for, while), flow-control (if-else), etc. These common constructs can be used to write an algorithm.
We write algorithms in a step-by-step manner, but it is not always the case. Algorithm writing is a process and is executed after the problem domain is well-defined. That is, we should know the problem domain, for which we are designing a solution.
Example
Let's try to learn algorithm-writing by using an example.
Problem − Design an algorithm to add two numbers and display the result.
Algorithms tell the programmers how to code the program. Alternatively, the algorithm can be written as −
In design and analysis of algorithms, usually the second method is used to describe an algorithm. It makes it easy for the analyst to analyze the algorithm ignoring all unwanted definitions. He can observe what operations are being used and how the process is flowing.
Writing step numbers, is optional.
We design an algorithm to get a solution of a given problem. A problem can be solved in more than one ways.
Hence, many solution algorithms can be derived for a given problem. The next step is to analyze those proposed solution algorithms and implement the best suitable solution.
Divide and Conquer
Divide/Break
Breaking the problem into smaller sub-problems
Conquer/Solve
This step receives a lot of smaller sub-problems to be solved.
Merge/Combine
Recursively combines all solved sub-problems.
Binary Search implementation
In binary search we take a sorted list of elements and start looking for an element at the middle of the list. If the search value matches with the middle value in the list we complete the search. Otherwise we eliminate half of the list of elements by choosing whether to proceed with the right or left half of the list depending on the value of the item searched. This is possible as the list is sorted and it is much quicker than linear search. Here we divide the given list and conquer by choosing the proper half of the list. We repeat this approach till we find the element or conclude about it's absence in the list.
When the above code is executed, it produces the following result:
Binary Search using Recursion
We implement the algorithm of binary search using python as shown below. We use an ordered list of items and design a recursive function to take in the list along with starting and ending index as input. Then the binary search function calls itself till find the the searched item or concludes about its absence in the list.
When the above code is executed, it produces the following result:
Backtracking
Backtracking is a form of recursion. But it involves choosing only option out of any possibilities. We begin by choosing an option and backtrack from it, if we reach a state where we conclude that this specific option does not give the required solution. We repeat these steps by going across each available option until we get the desired solution.
Below is an example of finding all possible order of arrangements of a given set of letters. When we choose a pair we apply backtracking to verify if that exact pair has already been created or not. If not already created, the pair is added to the answer list else it is ignored.
When the above code is executed, it produces the following result −
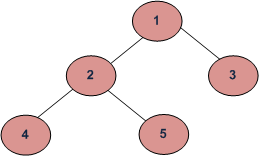
Tree Traversal Algorithms
Also check out PROGRAMIZ.
Traversal is a process to visit all the nodes of a tree and may print their values too. Because, all nodes are connected via edges (links) we always start from the root (head) node. That is, we cannot randomly access a node in a tree. There are three ways which we use to traverse a tree
Depth First Traversals: (a) In-order (Left, Root, Right) : 4 2 5 1 3 (b) Pre-order (Root, Left, Right) : 1 2 4 5 3 (c) Post-order (Left, Right, Root) : 4 5 2 3 1
Breadth First or Level Order Traversal : 1 2 3 4 5 Please see this post for Breadth First Traversal.
In-order Traversal
In this traversal method, the left subtree is visited first, then the root and later the right sub-tree. We should always remember that every node may represent a subtree itself.
Pre-order Traversal
In this traversal method, the root node is visited first, then the left subtree and finally the right subtree.
Post-order Traversal
In this traversal method, the root node is visited last, hence the name. First we traverse the left subtree, then the right subtree and finally the root node.
code by geekforgeeks.org
Output:
Level order traversal of a tree is breadth first traversal for the tree.
METHOD 1 (Use function to print a given level)
Algorithm: There are basically two functions in this method. One is to print all nodes at a given level (printGivenLevel), and other is to print level order traversal of the tree (printLevelorder). printLevelorder makes use of printGivenLevel to print nodes at all levels one by one starting from root.
METHOD 2 (Use Queue)
Algorithm: For each node, first the node is visited and then it’s child nodes are put in a FIFO queue.
https://www.hackerrank.com/challenges/tree-level-order-traversal/problem
Sorting Algorithms
Sorting refers to arranging data in a particular format. Sorting algorithm specifies the way to arrange data in a particular order. Most common orders are in numerical or lexicographical order.
The importance of sorting lies in the fact that data searching can be optimized to a very high level, if data is stored in a sorted manner. Sorting is also used to represent data in more readable formats. Below we see five such implementations of sorting in python.
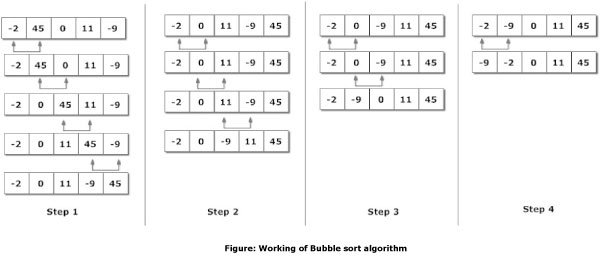
Bubble Sort
Merge Sort
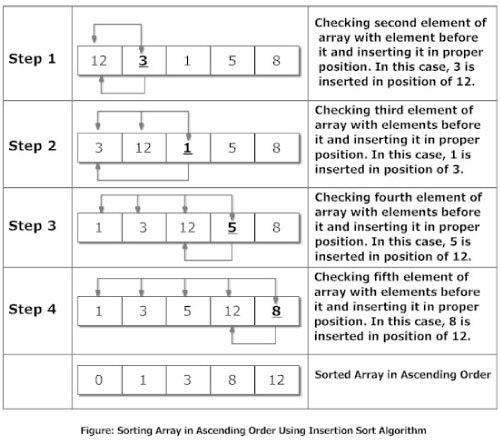
Insertion Sort
Shell Sort
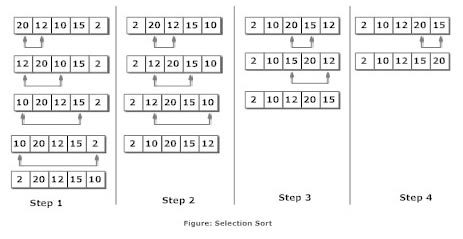
Selection Sort
Bubble Sort
Selection Sort
Explanation
Suppose, you want to sort elements in ascending as in above figure. Then,
The second element of an array is compared with the elements that appears before it (only first element in this case). If the second element is smaller than first element, second element is inserted in the position of first element. After first step, first two elements of an array will be sorted.
The third element of an array is compared with the elements that appears before it (first and second element). If third element is smaller than first element, it is inserted in the position of first element. If third element is larger than first element but, smaller than second element, it is inserted in the position of second element. If third element is larger than both the elements, it is kept in the position as it is. After second step, first three elements of an array will be sorted.
Similary, the fourth element of an array is compared with the elements that appears before it (first, second and third element) and the same procedure is applied and that element is inserted in the proper position. After third step, first four elements of an array will be sorted.
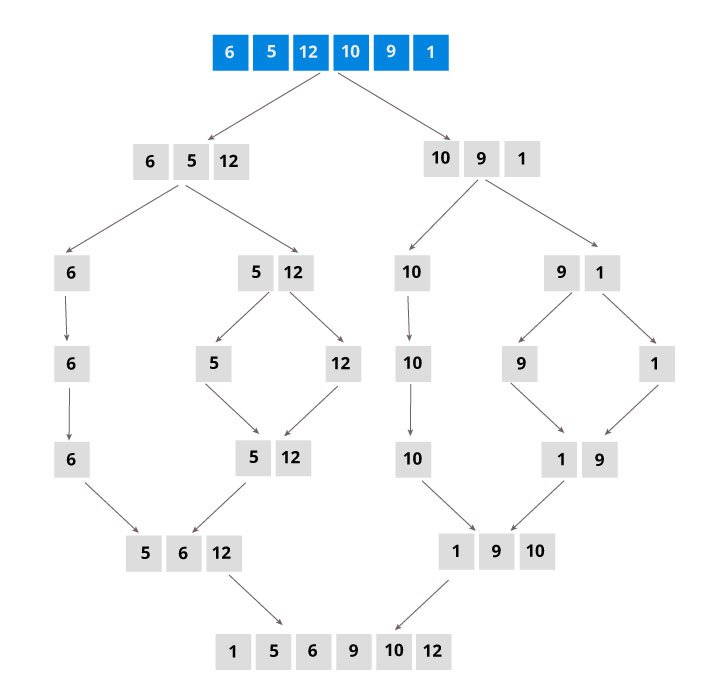
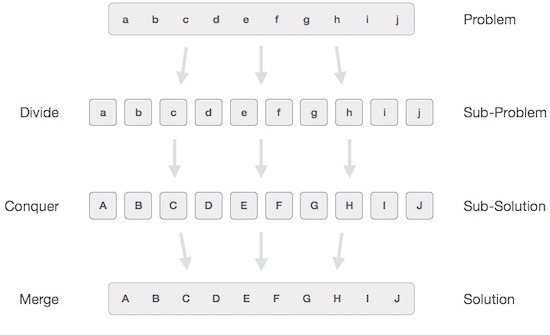
Merge Sort is a kind of Divide and Conquer algorithm in computer programrming. It is one of the most popular sorting algorithms and a great way to develop confidence in building recursive algorithms.
Divide and Conquer Strategy
Using the Divide and Conquer technique, we divide a problem into subproblems. When the solution to each subproblem is ready, we 'combine' the results from the subproblems to solve the main problem.
Suppose we had to sort an array A. A subproblem would be to sort a sub-section of this array starting at index p and ending at index r, denoted as A[p..r].
Divide If q is the half-way point between p and r, then we can split the subarray A[p..r] into two arrays A[p..q] and A[q+1, r].
Conquer In the conquer step, we try to sort both the subarrays A[p..q] and A[q+1, r]. If we haven't yet reached the base case, we again divide both these subarrays and try to sort them.
Combine When the conquer step reaches the base step and we get two sorted subarrays A[p..q] and A[q+1, r] for array A[p..r], we combine the results by creating a sorted array A[p..r] from two sorted subarrays A[p..q] and A[q+1, r]
Heap Sort
Heap Sort is a popular and efficient sorting algorithm in computer programming. Learning how to write the heap sort algorithm requires knowledge of two types of data structures - arrays and trees.
The initial set of numbers that we want to sort is stored in an array e.g. [10, 3, 76, 34, 23, 32] and after sorting, we get a sorted array [3,10,23,32,34,76]
Heap sort works by visualizing the elements of the array as a special kind of complete binary tree called heap.
What is a complete Binary Tree?
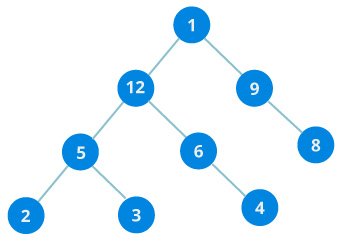
Binary Tree
A binary tree is a tree data structure in which each parent node can have at most two children
In the above image, each element has at most two children.
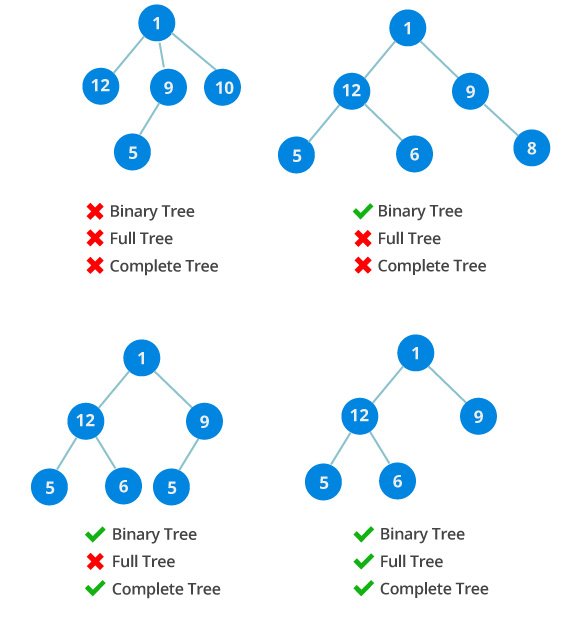
Full Binary Tree
A full Binary tree is a special type of binary tree in which every parent node has either two or no children.
Complete binary tree
A complete binary tree is just like a full binary tree, but with two major differences
Every level must be completely filled
All the leaf elements must lean towards the left.
The last leaf element might not have a right sibling i.e. a complete binary tree doesn’t have to be a full binary tree.
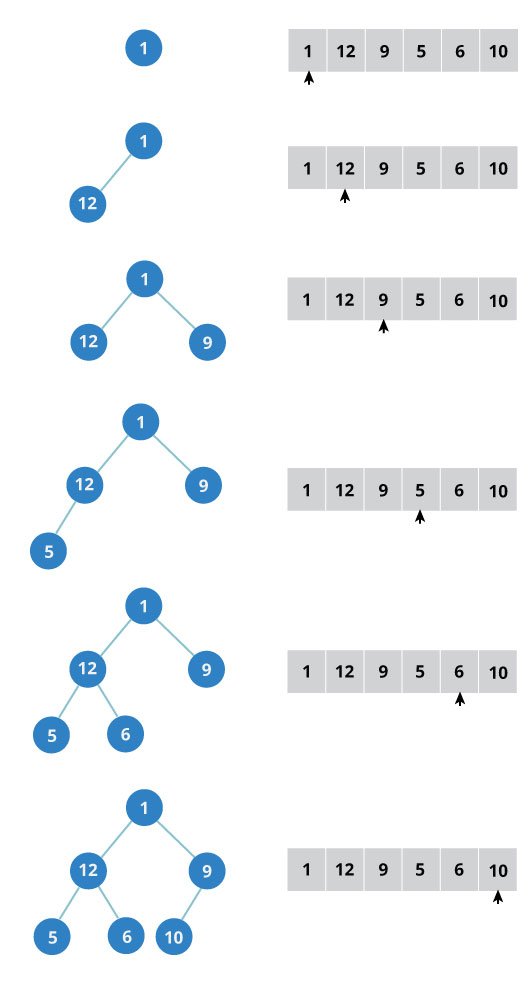
How to create a complete binary tree from an unsorted list (array)?
Select first element of the list to be the root node. (First level - 1 element)
Put the second element as a left child of the root node and the third element as a right child. (Second level - 2 elements)
Put next two elements as children of left node of second level. Again, put the next two elements as children of right node of second level (3rd level - 4 elements).
Keep repeating till you reach the last element.
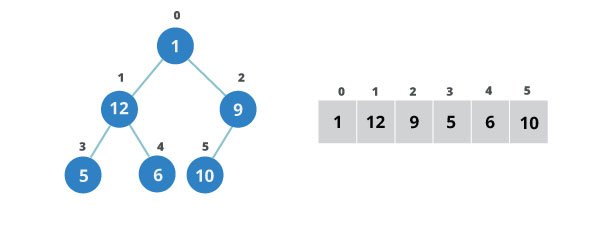
Relationship between array indexes and tree elements
Complete binary tree has an interesting property that we can use to find the children and parents of any node.
If the index of any element in the array is i, the element in the index 2i+1 will become the left child and element in 2i+2 index will become the right child. Also, the parent of any element at index i is given by the lower bound of (i-1)/2.
Let’s test it out,
Let us also confirm that the rules holds for finding parent of any node
Understanding this mapping of array indexes to tree positions is critical to understanding how the Heap Data Structure works and how it is used to implement Heap Sort.
What is Heap Data Structure ?
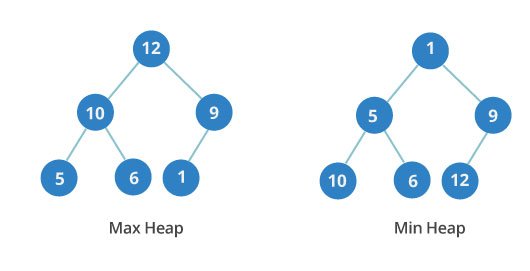
Heap is a special tree-based data structure. A binary tree is said to follow a heap data structure if
it is a complete binary tree
All nodes in the tree follow the property that they are greater than their children i.e. the largest element is at the root and both its children and smaller than the root and so on. Such a heap is called a max-heap. If instead all nodes are smaller than their children, it is called a min-heap
Following example diagram shows Max-Heap and Min-Heap.
How to “heapify” a tree
Starting from a complete binary tree, we can modify it to become a Max-Heap by running a function called heapify on all the non-leaf elements of the heap.
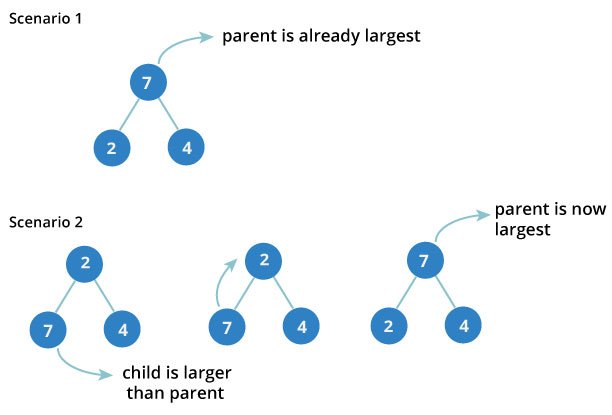
Since heapfiy uses recursion, it can be difficult to grasp. So let’s first think about how you would heapify a tree with just three elements.
The example above shows two scenarios - one in which the root is the largest element and we don’t need to do anything. And another in which root had larger element as a child and we needed to swap to maintain max-heap property.
If you’re worked with recursive algorithms before, you’ve probably identified that this must be the base case.
Now let’s think of another scenario in which there are more than one levels.
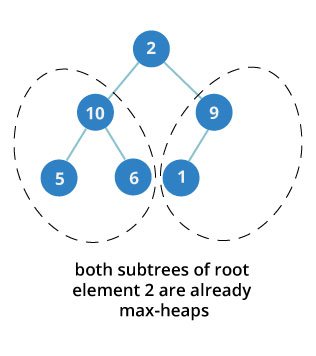
The top element isn’t a max-heap but all the sub-trees are max-heaps.
To maintain the max-heap property for the entire tree, we will have to keep pushing 2 downwards until it reaches its correct position.
Thus, to maintain the max-heap property in a tree where both sub-trees are max-heaps, we need to run heapify on the root element repeatedly until it is larger than its children or it becomes a leaf node.
We can combine both these conditions in one heapify function as
This function works for both the base case and for a tree of any size. We can thus move the root element to the correct position to maintain the max-heap status for any tree size as long as the sub-trees are max-heaps.
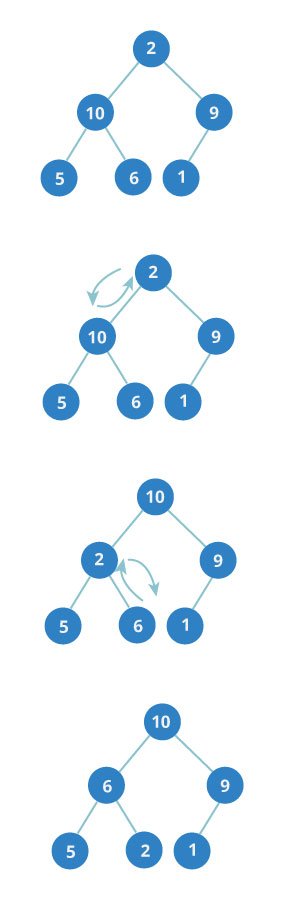
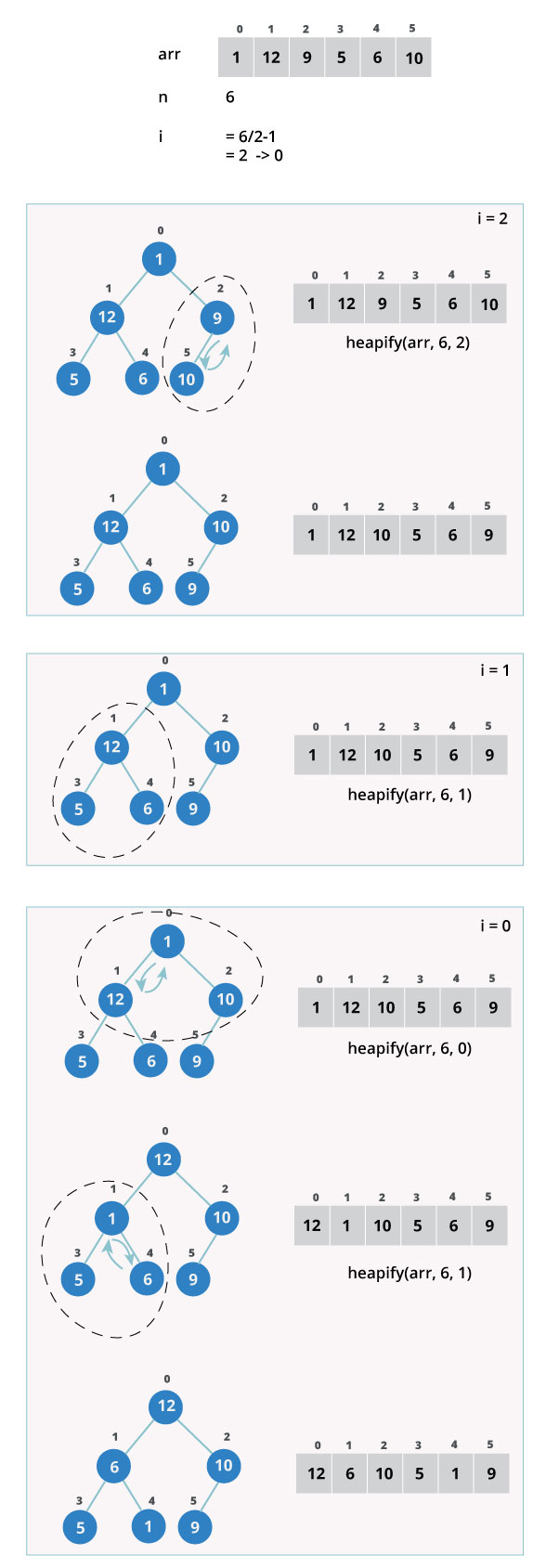
Build max-heap
To build a max-heap from any tree, we can thus start heapifying each sub-tree from the bottom up and end up with a max-heap after the function is applied on all the elements including the root element.
In the case of complete tree, the first index of non-leaf node is given by n/2 - 1. All other nodes after that are leaf-nodes and thus don’t need to be heapified.
So, we can build a maximum heap as
As show in the above diagram, we start by heapifying the lowest smallest trees and gradually move up until we reach the root element.
If you’ve understood everything till here, congratulations, you are on your way to mastering the Heap sort.
Procedures to follow for Heapsort
Since the tree satisfies Max-Heap property, then the largest item is stored at the root node.
Remove the root element and put at the end of the array (nth position) Put the last item of the tree (heap) at the vacant place.
Reduce the size of the heap by 1 and heapify the root element again so that we have highest element at root.
The process is repeated until all the items of the list is sorted.
The code below shows the operation.
Performance
Heap Sort has O(nlogn) time complexities for all the cases ( best case, average case and worst case).
Let us understand the reason why. The height of a complete binary tree containing n elements is log(n)
As we have seen earlier, to fully heapify an element whose subtrees are already max-heaps, we need to keep comparing the element with its left and right children and pushing it downwards until it reaches a point where both its children are smaller than it.
In the worst case scenario, we will need to move an element from the root to the leaf node making a multiple of log(n) comparisons and swaps.
During the build_max_heap stage, we do that for n/2 elements so the worst case complexity of the build_heap step is n/2*log(n) ~ nlogn.
During the sorting step, we exchange the root element with the last element and heapify the root element. For each element, this again takes logn worst time because we might have to bring the element all the way from the root to the leaf. Since we repeat this n times, the heap_sort step is also nlogn.
Also since the build_max_heap and heap_sort steps are executed one after another, the algorithmic complexity is not multiplied and it remains in the order of nlogn.
Also it performs sorting in O(1) space complexity. Comparing with Quick Sort, it has better worst case ( O(nlogn) ). Quick Sort has complexity O(n^2) for worst case. But in other cases, Quick Sort is fast. Introsort is an alternative to heapsort that combines quicksort and heapsort to retain advantages of both: worst case speed of heapsort and average speed of quicksort.
Application of Heap Sort
Systems concerned with security and embedded system such as Linux Kernel uses Heap Sort because of the O(n log n) upper bound on Heapsort's running time and constant O(1)upper bound on its auxiliary storage.
Although Heap Sort has O(n log n) time complexity even for worst case, it doesn’t have more applications ( compared to other sorting algorithms like Quick Sort, Merge Sort ). However, its underlying data structure, heap, can be efficiently used if we want to extract smallest (or largest) from the list of items without the overhead of keeping the remaining items in the sorted order. For e.g Priority Queues.
Python program for implementation of heap sort (Python 3)
Last updated